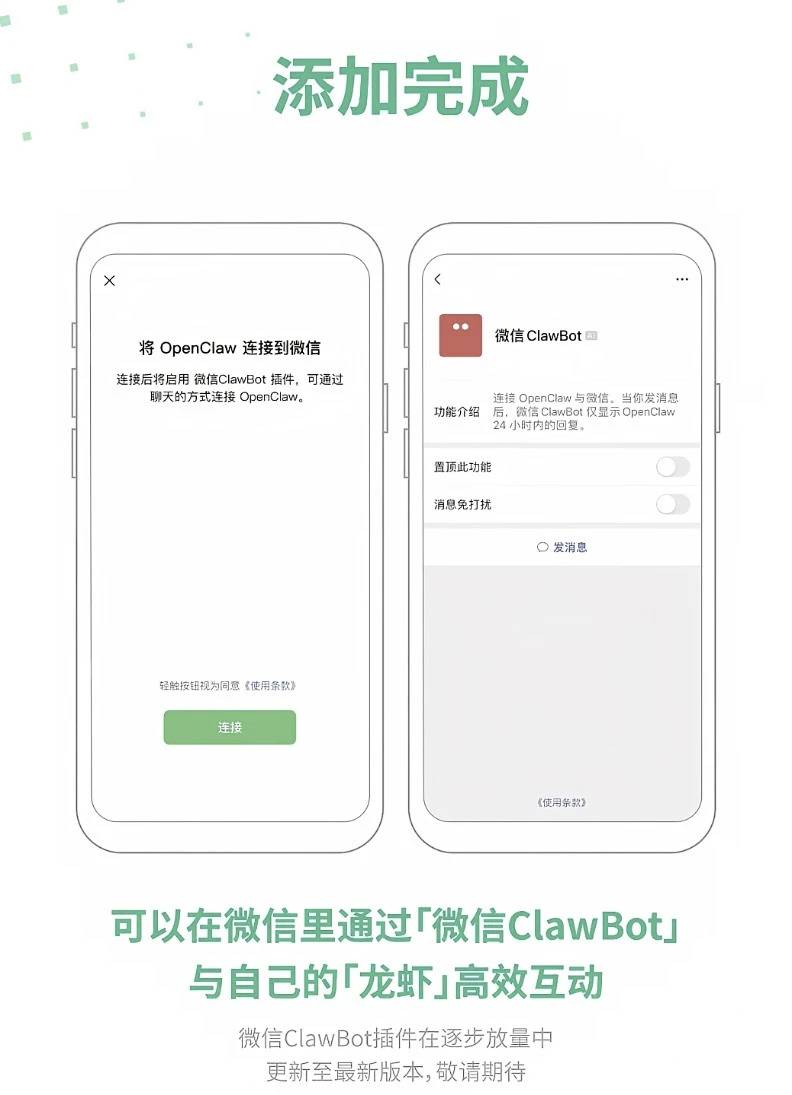
4月24日,连续跳票的DeepSeek V4预览版本终于正式上线并同步开源。
然而,这款被无数开发者和AI爱好者翘首以盼的大模型,其关注度却并未如预期般引爆舆论场。
简单来看,DeepSeek V4在技术架构上进行了深度优化,不仅将上下文窗口扩展至前所未有的百万tokens级别,还在推理效率和中文理解的多项基准测试中超越了前代产品,尤其在数学推理和代码生成能力上实现了显著跃升。
对于长期关注国产大模型的人来说,这无疑是值得喝彩的里程碑,但现实的传播声量却远不及其技术突破应有的分量。
这种"雷声小雨点也不大"的局面,很难不让人联想到几乎同期上演的另一场大戏。
就在DeepSeek V4正式上线前的不到二十四小时,OpenAI突然祭出了两记重拳——被内部称为"能力跨越式升级"的GPT-5.5,以及足以让创意行业侧目的图像生成模型Images 2.0。
前者以更强的多模态推理和实时交互能力席卷了所有技术评测榜单,后者则凭借媲美专业设计师的构图与风格迁移能力,在社交平台上掀起了一波又一波的"AI画图挑战"。
全球的AI爱好者、媒体和投资者几乎在同一瞬间被这两则消息牢牢吸引,舆论场的聚光灯毫无悬念地打在了OpenAI身上。
DeepSeek V4的发布窗口恰好撞上了这场"组合拳"的余波,从新闻推送的排序到话题热度的自然衰减,都处于极度被动的境地。
可以说,并非DeepSeek不够好,而是OpenAI用更密集、更戏剧化的方式抢走了几乎全部的风头,让一款原本足以引发行业震荡的模型只能在角落里独自闪光。
除了这种"撞车"式的尴尬,DeepSeek V4自身在过去几个月里的发布节奏也埋下了隐患。
从2025年底开始,团队就多次通过社交媒体和闭门沟通会释放"即将发布"的信号,但最终日期一推再推,从"春节后"延至"三月中旬",又从"四月上旬"滑向"四月底"。
每一次跳票都会引发一轮失望和调侃,这种"狼来了"的模式虽然在一定程度上维持了品牌的话题性,却也慢慢消耗了公众的耐心和期待阈值。
当V4真正到来时,很多人已经不再像最初那样第一时间打开测试页面,而是习惯性地先观望一下:这次是不是又会有变数?或者,是不是该等一等开源社区的评测再说?这种微妙的心态变化,使得产品发布本应具备的"爆点"效应被严重稀释。
尽管如此,如果因此就忽视DeepSeek V4的价值,那无疑是一种短视。
在GPT-5.5强大的光环下,V4依然展示出了国产大模型在原创架构和成本控制上的独特竞争力。它没有盲目追求参数量上的军备竞赛,而是在推理效率、长文本处理的中文适配度以及合规可控性上做了大量扎实的工作。
对于需要处理海量中文文档、进行复杂逻辑推理的企业级应用来说,DeepSeek V4提供了一条既高性能又经济可行的路径。
与此同时,它的发布也标志着国产大模型从"追赶"进入到"并跑"甚至局部"领跑"的阶段——至少在中文语义理解与长文本交互的某些细分维度上,DeepSeek已经具备了与全球顶尖模型同台较量的底气。
只可惜,技术世界的聚光灯往往更偏爱恰到好处的时机和持续稳定的信任积累。DeepSeek V4这一次没能成为舞台中央的主角,但它埋下的技术种子,或许会在下一轮发布中,开出更加令人惊艳的花。
微信扫一扫,分享到朋友圈