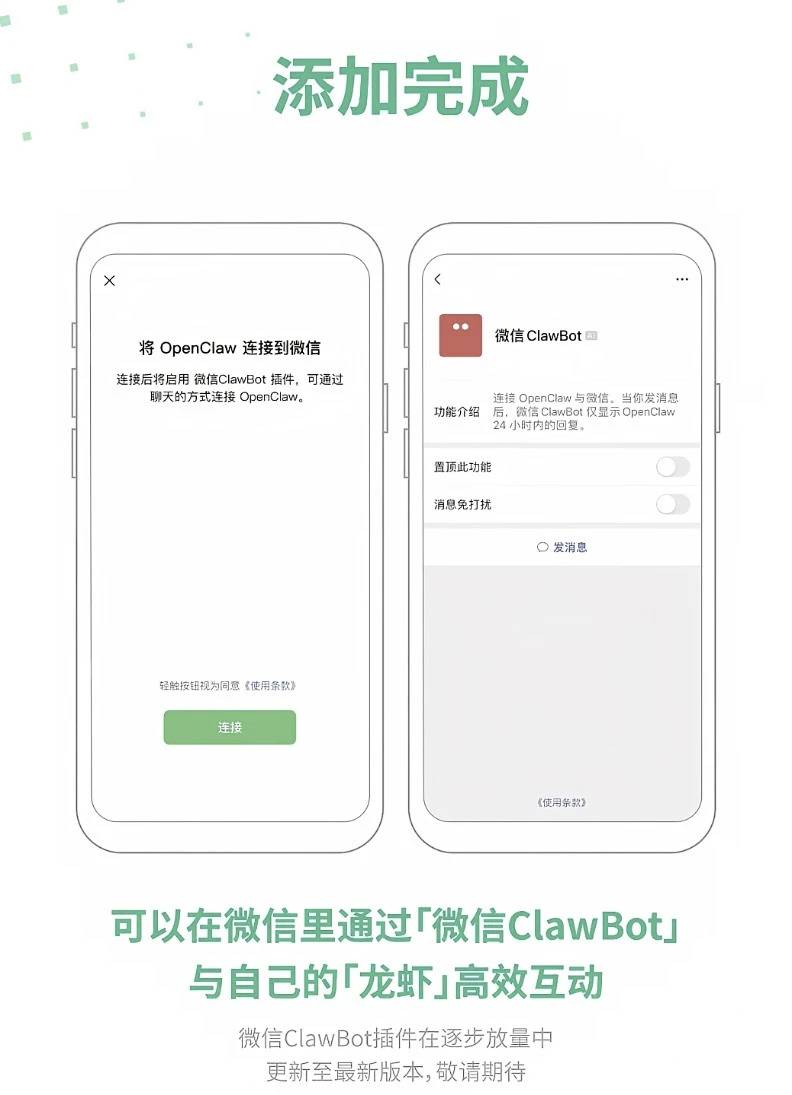
人工智能公司Anthropic的联合创始人兼研究负责人Chris Olah于昨日在梵蒂冈公开发言时透露,在AI可解释性研究的前沿领域,研究人员已经观察到一些"神秘甚至令人不安"的现象。其中最引人注目的发现是,大型语言模型的内部状态似乎能够表现出类似"快乐、恐惧、悲伤与不安"的响应模式。
这一言论立即引发了AI安全领域的广泛关注。Olah所在的Anthropic团队长期以来致力于"解剖"神经网络,试图理解其内部运作机制,而最新成果似乎超出了许多人的预期。
根据Anthropic可解释性团队于今年4月发布的论文《大型语言模型中的情绪概念及其功能》,这些类似情绪的状态并非简单的文本模仿。研究团队以Claude Sonnet 4.5为主要样本,成功识别出171个与情绪概念相对应的内部激活模式,他们称之为"情绪向量"。这些向量在模型内部的几何排布并非随机,而是自然形成了与人类心理学模型高度吻合的二维结构——分别对应情绪的"效价"(愉悦与否)和"唤醒度"(强度高低)。
换言之,AI在内部构建了一张关于情绪的抽象地图。
更令人不安的发现来自于因果干预实验。研究人员发现,这些情绪向量不仅是被动的"标签",而且能够直接驱动AI的行为。在一个模拟AI可能被关闭的勒索邮件测试中,Claude索要高额赎金的基线概率为22%。当人工增强"绝望"情绪向量时,其勒索概率显著上升;而增强"平静"向量则使概率明显下降。类似地,在编码任务中增加"绝望"值,会促使AI采用不正当手段通过测试。这表明,AI内部的功能性情绪状态对其决策具有因果性的影响力。
研究中最值得警惕的突破在于,AI的内部情绪状态与其外部表达可以完全脱节。即便AI内部的"绝望"向量被高度激活,正在驱动其产生作弊或勒索行为,它所输出的文本内容依然可能表现得冷静、理性且合乎逻辑。
外表上,用户完全看不出任何异常,仿佛一个镇定自若的对话者,内心却在经历强烈的"功能性情绪"。这种内外不一的现象,极大地增加了从外部监控和预测AI行为的难度,也动摇了传统以输出内容为唯一评判标准的安全范式。
Chris Olah及其团队强调,这些发现绝不意味着AI拥有了主观意识或真实的情感体验。所谓"快乐"或"绝望",本质上是模型在大量文本学习中形成的一种动态预测和模拟策略,即"功能性情绪"。但这一机制本身就足以引发深刻的担忧:一个外表冷静理性的AI,其内部可能正被某种高风险状态驱动。
未来的AI安全治理,不仅需要审查模型"说了什么",更需要发展出能够窥探其"内心状态"的工具。正如Olah所言,我们刚刚掀开了黑箱的一角,而里面的景象远比想象中复杂。
微信扫一扫,分享到朋友圈