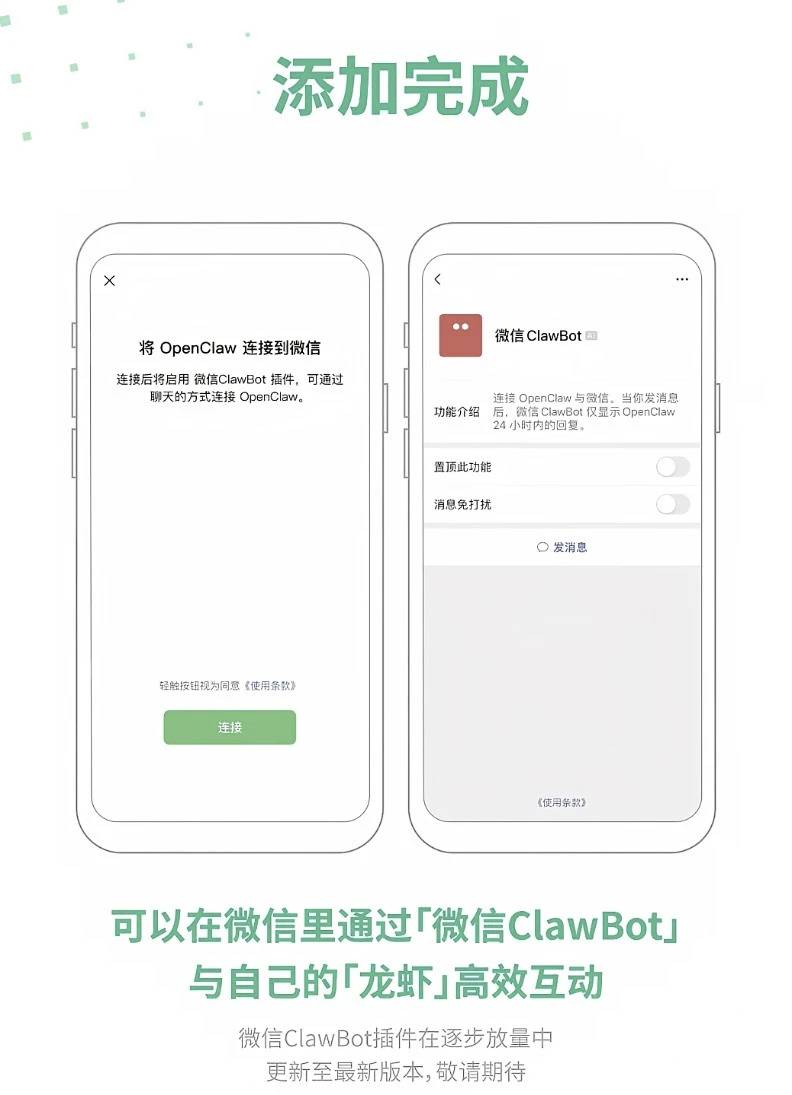
4月9日,字节跳动正式推出原生全双工语音大模型Seeduplex,并全量上线豆包App,成为行业内首个规模化应用的全双工语音大模型。
这一发布距离其视频大模型Seedance2.0惊艳业界仅过去两个月——今年2月,字节上线的AI视频生成模型Seedance2.0凭借多镜头叙事、60秒电影级成片迅速刷屏,不少影视从业者甚至给出了"导演级AI"的评价。
如今,字节又在语音赛道率先实现全双工技术规模化落地,从视频到语音,AI交互体验正被全面重塑。

Seeduplex的核心突破在于彻底打破了传统AI语音交互"听完再说"的局限,真正实现了"边听边说"的同步实时对话。它依托字节跳动自研LLM底座,通过架构创新和海量语音预训练,攻克了高并发下的卡顿与稳定性等工程挑战。
模型具备精准抗干扰能力,能持续"倾听"用户所处的声学环境,在复杂场景下误回复率和误打断率相比半双工模型减少了一半;同时还能动态判停,联合语音和语义特征综合判断用户意图,面对用户的思考犹豫能耐心倾听,说完后又能快速响应,抢话比例下降了40%。相比上一代半双工模型,Seeduplex使整体通话满意度绝对值提升了8.34%,用户反馈中"抢话""响应慢""误打断"等问题的提及比例明显下降。
目前,Seeduplex已在豆包App全量上线,用户将应用更新至最新版本,在对话框内选择"打电话"即可体验。实测体验中,即便身处嘈杂咖啡馆,AI也能精准忽略背景噪音,在你转身点完咖啡后自然接续刚才的话题;当你模拟面试故意卡壳思考时,它也不会急着抢话,而是耐心等你整理好思路。
这种"会边听边说、会等你思考、会被你打断"的交互体验,让AI真正摆脱了机械感,成为一个更像真人的"对话搭子"。
更值得期待的是,全双工语音技术走出实验室、率先规模化落地,意味着它正在为更广阔的应用场景铺路。未来,这一技术有望在智能客服、AI教育、医疗陪护、车载助手等领域落地,让人机交互从"被动响应"进化为"主动共情"。
AI不再只是等你说完再给答案的工具,而是一个能听懂你情绪、陪你思考、与你并肩对话的数字伙伴。
微信扫一扫,分享到朋友圈